Apache Kafka
[Apache Kafka] 카프카 컨슈머 파헤치기
jngsngjn
2024. 11. 17. 02:17
컨슈머 내부구조
리더 파티션을 가진 브로커가 컨슈머에게 데이터를 전송함
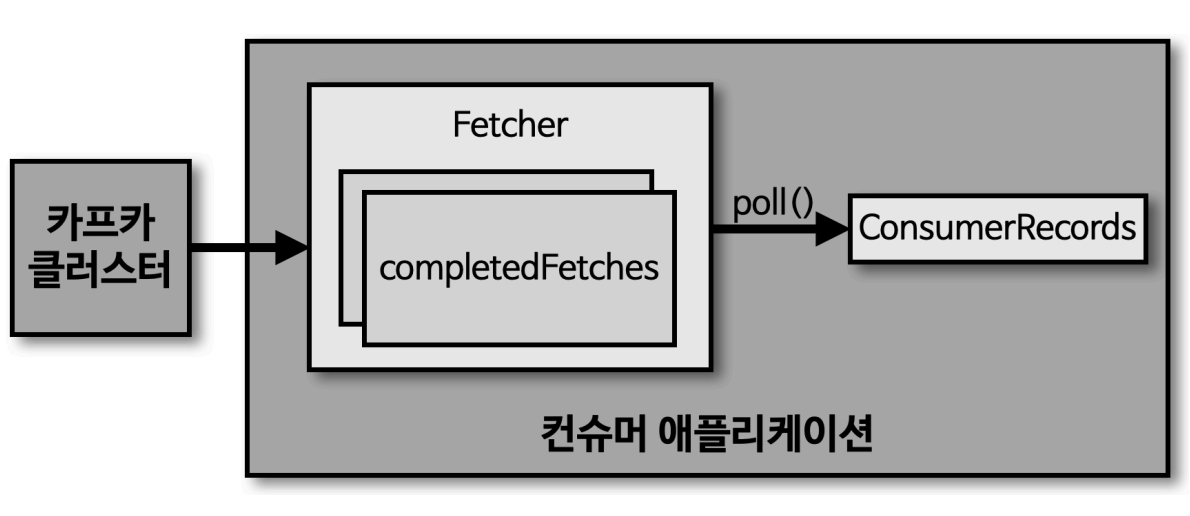
(1) Fetcher
- Fetcher : 컨슈머 내부에서 데이터를 가져오는 비동기 백그라운드 쓰레드
- 리더 파티션으로부터 데이터를 미리 가져와 버퍼에 저장함
- fetch.min.bytes, fetch.max.wait.ms 같은 설정으로 Fetch 동작을 최적화 가능
(2) completedFetches
- Fetcher가 데이터를 충분히 가져오면 completedFetches 큐에 저장함
- completedFetches는 전송이 완료된 Fetch 요청을 나타냄
(3) poll()
- 컨슈머는 poll() 메서드를 호출하여 Fetcher가 가져온 데이터를 읽음
- completedFetches 큐에 쌓여 있는 레코드들을 ConsumerRecords로 반환
(4) ConsumerRecords
- 컨슈머 애플리케이션에서 처리할 데이터를 포함한 레코드 모음
- 구성요소
- 레코드 데이터 : 실제 메시지
- 오프셋 정보 : 각 메시지의 위치 추적
- 파티션 정보 : 메시지가 속한 파티션
컨슈머 그룹

- 특정 토픽에 대해 어떤 목적에 따라 데이터 처리하는 컨슈머를 묶은 것
- 컨슈머 그룹 내 컨슈머들은 모두 동일한 로직을 가짐 (일반적으로)
- 기본적으로 컨슈머 그룹이 특정 토픽을 구독하면 해당 토픽의 모든 파티션을 읽어들임 (어사인으로 조정 가능)
컨슈머 그룹의 컨슈머가 파티션 개수보다 많을 경우

→ 파티션은 단 하나의 컨슈머에게만 연결될 수 있기 때문에 유휴 컨슈머 발생,, (불필요 쓰레드)
리밸런싱
컨슈머 그룹 내 컨슈머와 파티션 간의 매핑을 재조정하는 과정

- 리밸런싱을 통해 파티션-컨슈머 매핑을 재구성하여, 새로 추가되거나 제거된 컨슈머를 반영할 수 있음
- 리밸런싱이 일어나는 주요 두 가지 상황
- 컨슈머가 부족한 상황에 컨슈머가 추가된 경우, 새롭게 추가된 컨슈머에게 파티션 할당
- 특정 컨슈머에 장애가 발생한 경우, 해당 컨슈머에 매핑되어 있던 파티션을 다른 컨슈머에 매핑
- 리밸런싱 중 데이터 처리가 일시적으로 중단될 수 있지만, 최적화 기법(스태틱 멤버십, 리밸런싱 지연 설정)을 통해 이를 최소화할 수 있음
- 리밸런싱은 컨슈머가 데이터를 처리하는 도중에 언제든 발생할 수 있으므로 리밸런싱에 대응하는 코드를 작성해야 함
consumer.subscribe(Arrays.asList("my-topic"), new ConsumerRebalanceListener() {
// 컨슈머가 현재 할당된 파티션을 잃게 될 때 호출됨
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
// 기존 파티션에 대한 작업 정리 (예: 커밋)
}
// 컨슈머가 새로운 파티션을 할당받았을 때 호출됨
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
// 새로 할당된 파티션 초기화
}
});커밋
컨슈머가 현재 처리한 메시지의 오프셋(offset)을 브로커에게 전달하여 기록하는 것

- 브로커 내부에서 사용되는 토픽(__consumer_offsets)에 기록됨
- 오프셋 커밋이 제대로 이루어지지 않는다면 데이터 처리의 중복이 발생할 수 있으므로 커밋이 잘 되었는지 검증해야 함
- 카프카 컨슈머는 기본적으로 자동 커밋 기능을 제공함
- enable.auto.commit : 기본값 true
- auto.commit.interval.ms : 기본값 5000
- 자동 커밋 기능은 간편하지만 데이터 정합성에 문제가 생길 수 있으므로 수동 커밋을 사용하는 것이 안전함
어사이너 (Assignor)
- 컨슈머 그룹에서 파티션과 컨슈머 간의 매핑을 결정하는 알고리즘
- 카프카 라이브러리에서 기본적으로 몇 가지 어사이너가 제공됨
- ConsumerPartitionAssignor 인터페이스를 구현하여 커스텀 어사이너 사용 가능
- 일반적으로 파티션과 컨슈머를 1:1 매핑하여 사용하므로 이 부분에 대한 학습은 일단 이 정도만!
(1) RangeAssignor (default)
(2) RoundRobinAssignor
(3) StickyAssignor
(4) CooperativeStickyAssignor
컨슈머 주요 옵션
필수 옵션
(1) bootstrap.servers
(2) key.deserializer
(3) value.deserializer
선택 옵션
(1) group.id
- 컨슈머 그룹 아이디 지정
- subscribe() 메서드로 토픽을 구독하여 사용할 때는 이 옵션을 필수로 설정해줘야 함
- 기본값 : null
(2) auto.offset.reset
- 컨슈머 그룹이 파티션을 읽을 때 저장된 컨슈머 오프셋이 없는 경우 어느 오프셋부터 읽을지 선택하는 옵션
- latest (default) : 가장 최근 오프셋부터 읽음
- earliest : 가장 오래된 오프셋부터 읽음
- none : 먼저 커밋 기록이 있는지 확인 후 기록이 없으면 오류를 반환하고, 기록이 있다면 기존 커밋 기록 이후부터 읽음
- 컨슈머 오프셋이 있다면 이 옵션 값은 무시됨
- 이미 파티션에 레코드가 적재되어 있고, 새로 컨슈머 그룹을 생성했을 때만 사용하는 옵션임
(3) enable.auto.commit
- 자동 커밋 사용 여부
- 기본값 : true
(4) auto.commit.interval.ms
- 자동 커밋 옵션이 true일 때, 자동 커밋의 간격을 지정하는 옵션
- 기본값 : 5000 (5초)
(5) max.poll.records
- poll() 메서드를 통해 반환되는 records의 최대 개수 지정
- 기본값 : 500
(6) max.poll.interval.ms
- poll() 메서드를 호출 시간 최대 간격
- 이 설정 시간이 지나도록 poll() 메서드가 호출되지 않으면 컨슈머가 더 이상 메시지를 처리하지 않는다고 판단하여 리밸런싱 시작
- 기본값 : 300000 (5분)
(7) heartbeat.interval.ms
- 하트비트를 전송하는 시간 간격 설정 (컨슈머가 보내는 것)
- 기본값 : 3000 (3초)
(8) session.timeout.ms
- 브로커에 대한 컨슈머의 타임아웃 설정
- 마지막 하트비트 이후 설정한 시간이 지났으면 타임아웃으로 간주하여 리밸런싱 시작
- 이 설정 값을 너무 작게 하면, 장애가 난 것이 아니지만 리밸런싱이 자주 일어날 수 있음
- 기본값 : 45000 (45초)
(9) isolation.level
- 트랜잭션 프로듀서가 레코드를 트랜잭션 단위로 보낼 경우 사용하는 옵션
멀티쓰레드 컨슈머
(1) 멀티 프로세스
- 각 프로세스가 컨슈머를 실행하여 독립적으로 파티션을 처리하는 방식
- 특정 프로세스에 장애가 발생해도 다른 프로세스에 영향을 미치지 않음
- 각 JVM 프로세스 배포 과정의 어려움이 있을 수 있음
- 각 프로세스가 독립적으로 실행되므로 컨텍스트 공유가 어려움
- 높은 안정성이 중요한 경우 사용
(2) 1 프로세스 + 멀티쓰레드
- 하나의 프로세스 내에서 여러 쓰레드를 실행하여 데이터를 병렬 처리하는 방식
- 프로세스가 하나이기 때문에 배포 과정이 단순함
- 쓰레드 간 데이터 공유가 쉬움
- JVM 리소스를 더 효율적으로 사용
- 특정 쓰레드에 장애 발생 시 전체 프로세스에 영향을 미칠 수 있음
- 배포 간소화와 리소스 효율성이 중요한 경우 사용
컨슈머 랙(LAG)

- 컨슈머 랙 : 파티션의 최신 오프셋(LOG-END-OFFSET)과 컨슈머 오프셋(CURRENT-OFFSET) 간의 차이
- 컨슈머 랙 모니터링을 통해 컨슈머가 정상 동작하는지 알 수 있음 → 컨슈머 장애 확인, 파티션 개수 결정에 참고 가능
- 컨슈머 랙은 파티션별로 존재함
- 리밸런싱 과정에서 컨슈머 랙이 일시적으로 급증할 수 있음
- 컨슈머 그룹 내에서 파티션을 재분배하는 동안 기존 컨슈머는 파티션의 메시지 처리를 중단하기 때문
- 리밸런싱 시작 전 커밋을 하지 못한 경우
- 리밸런싱 자체의 시간 소모
- 리밸런싱 중 랙 증가 완화하는 방법
- 세션 타임아웃 및 하트비트 간격을 조정하여 리밸런싱 빈도를 줄임
- 스태틱 멤버십 사용 → 리밸런싱 후에도 동일한 컨슈머가 파티션 유지 가능
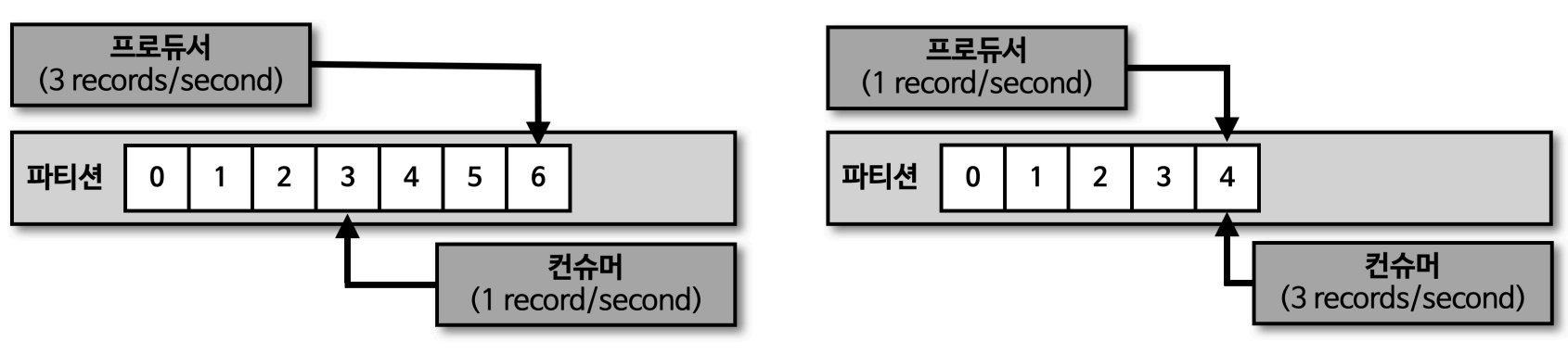
- 컨슈머 랙은 프로듀서와 컨슈머의 데이터 처리량의 차이로 인해 발생함
- 왼쪽 그림의 경우 컨슈머 랙은 0으로 지연이 없음을 뜻함
- 컨슈머 랙이 높다는 것은 그만큼 지연이 많이 발생한다는 뜻
- 지연이 발생할 경우 파티션 개수와 컨슈머 개수를 늘림으로써 병렬 처리량을 늘려 컨슈머 랙을 줄일 수 있음
- 컨슈머 랙 모니터링을 통해 파티션에 발생한 이슈도 확인할 수 있음
- 일부 파티션의 랙이 유난히 높다면, 컨슈머 그룹 내에서 특정 파티션이 불균형하게 처리되고 있을 가능성이 있음 → 파티션 키 재설계 또는 컨슈머의 파티션 할당 로직 확인
- 리더-팔로워 구조에서 특정 브로커가 과도한 리더 역할을 맡고 있으면, 해당 파티션에서 처리 병목이 발생할 수 있음 → 리더 재분배
컨슈머 랙 모니터링 방법
(1) kafka-consumer-groups.sh
- 간단하지만 일회성에 그치고 지속적으로 확인하기 어려움
(2) metrics()
- 자바 기반 공식 라이브러리
- 컨슈머가 정상 동작하는 경우에만 확인 가능
- 모든 컨슈머 애플리케이션에 모니터링 코드를 중복해서 작성해야 함
(3) 외부 모니터링 툴
- 컨슈머 랙을 포함한 종합 모니터링 툴 : Datadog, Confluent Control Center…
- Burrow : 컨슈머 랙 모니터링만 가능
- 모든 토픽, 모든 컨슈머 그룹에 대한 컨슈머 랙 실시간 모니터링 가능
Burrow
- 링크드인에서 개발하여 오픈소스로 공개한 컨슈머 랙 모니터링 툴
- 다수의 카프카 클러스터를 동시에 연결하여 확인 가능
- 한 번의 설정으로 다수의 카프카 클러스터의 컨슈머 랙 확인 가능
- 컨슈머와 파티션의 상태를 단순히 컨슈머 랙의 임계치로 나타내지 않았다는 점이 큰 장점
- 컨슈머 랙이 임계치에 도달할 때마다 알람을 받는 것은 무의미한 일 (일시적인 현상일 수 있기 때문)
- REST API 기반
- 버로우는 임계치가 아닌 슬라이딩 윈도우 계산을 통해 파티션과 컨슈머의 상태를 표현함
- 파티션의 상태 : OK, STALLED, STOPPED
- 컨슈머의 상태 : OK, WARNING, ERROR